Dune 架构分析
Dune 的前端体验
我们在 Dune 发起一个 query 请求,背后的系统是如何运行的?我们可以从前端的体验来推测一下, F12 打开浏览器控制台,观察 Network, 可以看到点击 run query 会触发多个异步查询请求,我们一个一个分析。 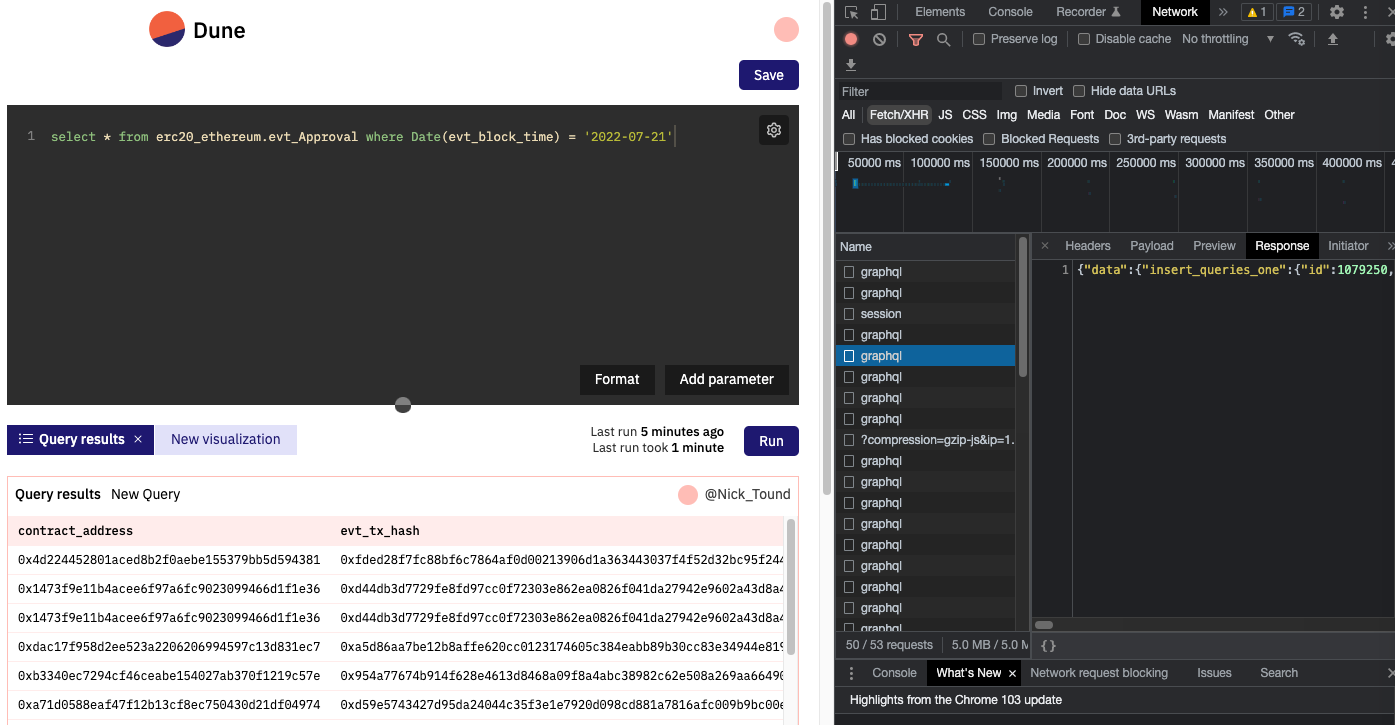
可以看到所有请求访问的地址是 https://core-hsr.duneanalytics.com/v1/graphql 从名字上可以看出和 graphql 有关,背后的服务是 hasura, hasura 是开源的 graphql 服务,只需要配置好 database,就可以自动读取 table schema 并生成对应的 graphql 接口。
(怎么看出来是 hasura 的?刚好用过~)
接下来看第一个 request body,这是将用户写的 SQL 提到到数据库中
{
"operationName": "UpsertQuery",
"variables": {
"object": {
"id": 1079250,
"dataset_id": 1,
"name": "New Query",
"query": "select * from erc20_ethereum.evt_Approval where Date(evt_block_time) = '2022-07-21'",
"user_id": 56489,
},
"session_id": 56489
}
}
第二个 request body, 告诉后端执行刚刚用户提交的 SQL,注意是通过 query_id 来定义一个 query 的,而且 sql query 是异步的。
{
"operationName": "ExecuteQuery",
"variables": {
"query_id": 1079250,
"parameters": []
}
}
hasura 会调度一个 engine 来完成 sql query。不过会同步返回一个 job_id 给前端
{
"data": {
"execute_query": {
"job_id": "6c1969e8-1398-48db-900d-6fd7ed5247df",
"__typename": "execute_query_response"
}
}
}
第三至 N 个 request body, 不断轮询后端(通过job_id),查看 sql 的执行状态
{
"operationName": "GetQueuePosition",
"variables": {
"job_id": "6c1969e8-1398-48db-900d-6fd7ed5247df"
}
}
等后端返回 sql query 完成时,前端会发起取数请求
{
"operationName": "FindResultDataByJob",
"variables": {
"job_id": "6c1969e8-1398-48db-900d-6fd7ed5247df"
}
}
这样用户就看到了查询结果
OK 我们可以得到初步结论,Dune 的查询是异步式的,使用 hasura 来管理用户是 query 生命周期。
查询引擎
刚刚收到 hasura 会调度 engine 来完成 sql query,Dune V1 是直接用 Postgres 集群,后面性能更不上了,就出现了 Dune Engine V2
从文档的介绍可知,V2 的 engine 是 “Instance of Apache Spark hosted on Databricks” ,托管在 Databricks 的 Spark 集群,SQL方言也改为了 DatabricksSQL。
DatabricksSQL
和 Bigquery 类似,是一个 serverless sql 数据湖计算平台,而且也是 sql only, 不过背后跑的还是 Spark,可以看看这个 video 快速了解下。
在 Dune 上实测,V2 的查询速度会比较慢,使用日期过滤查询 transactions 表,需要 1min 左右。
值得思考的是,几家区块链数据分析平台一致选择了这类 sql only 的数据湖方案
- Nansen:Bigquery
- Footprint:Bigquery
- Flipside:Snowflake
- Dune V2:DatabricksSQL(Dune V2 终于开始跟上来了)
为什么? 我觉得有几点原因:
- 存储数据量大,像 BSC Solana 链底层数据有 TB 级别
- 数据湖方案无需运维,开箱即用
- 绝大部分指标,使用 SQL 就可以完成计算
抽象 Abstractions
Dune 对常用的指标做了整合,称为 Abstractions,Abstraction in DuneV2 will run on dbt (data build tool).
sql only 的模式下,使用 dbt 是一个必然选择, sql 不像代码那样好管理,而 dbt 为 sql 提供了工程化的能力。
总结
最后,总结一下,Dune V2 组件和实现方案:
- 链数据同步,chain --> databricks sql:方案未知
- event logs:方案未知
- chain data 存储: databricks sql
- 计算引擎: databricks sql
- query api: hasura
- web ui: 方案未知
延伸话题,Dune 为何选择 SQL?
以下纯粹是个人见解
- sql 易上手, 更接近自然语言,适用人群广
- 业务架构简单,Dune 只需要准备好 chain 底层数据,例如 transactions token_transfers logs 等,还有解析好的 event 数据,以及 price 数据等, 这些数据都是比较底层的,很容易保障数据质量,用户直接基于底层数据算出指标,没有中间表和复杂的调度流程,每次都是全量计算,用户有非常广阔的探索空间。
- 技术架构简单,使用异步查询+缓存,sql 的计算压力都压给 databricks sql,牺牲快速查询的体验,保证了大数据查询的能力
坏处是什么?
- sql 无法完成复杂的指标计算,或者稍微复杂的计算需要几百行 sql 才能完成
- 每次查询都是从底层数据算起,有大量的重复计算,浪费算力